W przypadku pytań otwartych, w których ankietowany ma za zadanie wskazać pojedynczą nazwę np. produktu, z którego korzysta, kategoryzacja może wydawać się prosta, gdyż zazwyczaj będą występowały powtórzenia wskazywanych kategorii. W praktyce jednak ten proces staje się bardziej złożony. W odpowiedziach często pojawiają się literówki, różne formy zapisu lub też błędy ortograficzne. Warto podkreślić, że problem ten dotyczy nie tylko pytań otwartych w badaniach ankietowych. Wszędzie tam, gdzie dopuszczamy możliwość ręcznego wpisania wartości bez wcześniej zdefiniowanego słownika (np. nazwy klientów, produktów, marek) mogą pojawiać się błędy w zapisie. Ujednolicenie zapisu takich danych wymaga dużego nakładu czasu, dlatego też przydatne będą tu metody pomagające zautomatyzować ten proces.
W tym wpisie zaprezentuję funkcjonalności, które nie tylko ułatwią pracę z kategoryzacją krótkich odpowiedzi z pytań otwartych, ale również będą pomocne przy znacznie bardziej rozbudowanych wypowiedziach.
Na potrzeby tego przykładu posłużę się danymi ze zrealizowanej w Krakowie sondy ulicznej. Oprócz pytań dotyczących interesującego badacza zagadnienia, w metryczce znajdowało się również pytanie o dzielnice miasta, w której respondent mieszkał. Wykorzystano w tym celu pytanie otwarte. Po zakończeniu badania wyniki zostały wprowadzone do komputera.
Przyjrzyjmy się danym. Jak można zauważyć, zapis nazw dzielnic jest bardzo zróżnicowany. Pojawiają się nazwy z literówkami, nazwy rozpoczynające się z małej litery, błędy ortograficzne itp. W przypadku dzielnicy Bieżanów występuje kilka wariantów zapisu. Należy ujednolicić nazwy, ponieważ nazwa „Bieżanów” to inny zestaw znaków niż „Biezanow”, tym samym automatyczne rekodowanie zmiennych stworzy nam kilka kategorii dla tej dzielnicy. Podobna sytuacja pojawia się w przypadku innych dzielnic.
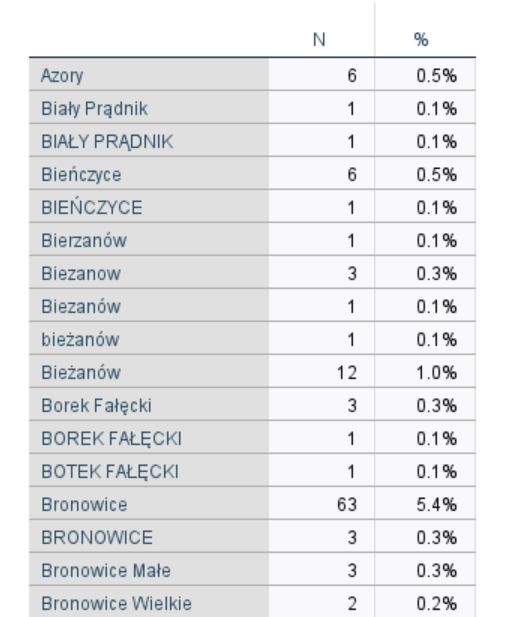
Rysunek 1. Fragment tabeli przedstawiający nazwy dzielnic Krakowa, które zostały wprowadzone do zbioru danych
Naszym celem będzie ujednolicenie zapisu, a następnie porównanie podobieństwa zapisu nazwy z docelowymi nazwami pochodzącymi z naszego słownika kategorii (w tym wypadku będzie to lista 18 dzielnic Krakowa).
Do ujednolicenia zapisu wykorzystamy na początku procedurę Wyczyść tekst. Jej zastosowanie zostało szerzej opisane w wpisie Czyszczenie danych tekstowych w PS IMAGO PRO, dlatego w tym artykule zaprezentuje jedynie główne funkcje, jakie pozwolą ujednolicić zapis. Aby skorzystać z procedury należy przejść do menu Predictive Solutions -> Transformacje -> Wyczyść tekst. Po wskazaniu zmiennej źródłowej oraz nowej zmiennej wybieram opcje, które zamienią wszystkie duże litery na małe, usuną zwielokrotnione znaki oraz znaki przystankowe, a także polskie znaki diakrytyczne. Ta ostania opcja wynika z tego, że niektóre nazwy dzielnic były zapisywane bez polskich znaków diakrytycznych, np. Prądnik biały - Pradnik bialy.
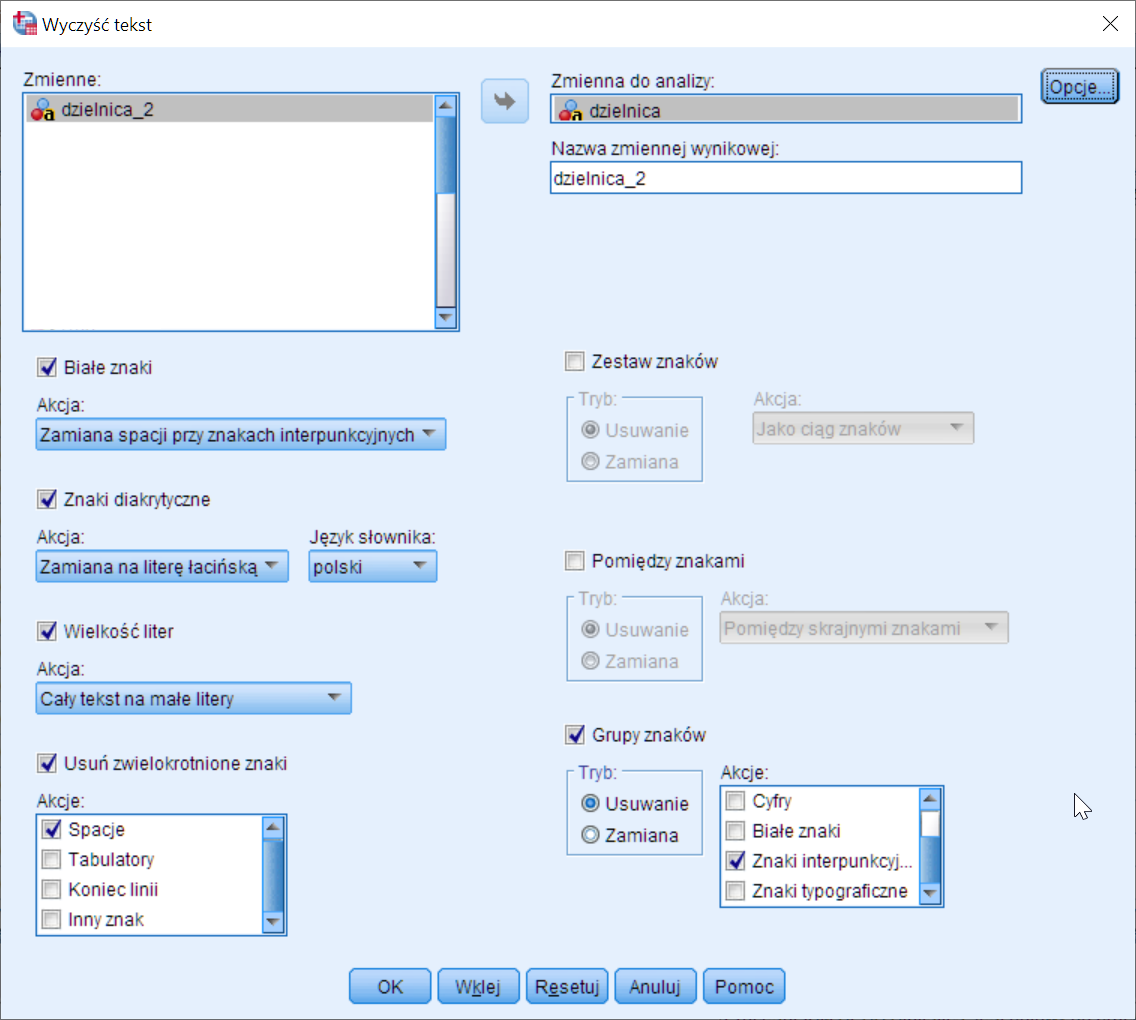
Rysunek 2. Wybrane opcje w procedurze Wyczyść tekst
Po wykonaniu procedury została stworzona nowa zmienna, w której nazwy zostały ujednolicone. Jeśli teraz zastosowalibyśmy automatyczną kategoryzacje, rezultat działania byłby już na tym etapie lepszy niż przed ujednoliceniem. Warto jednak zauważyć, że w danych pojawiają się również błędy w zapisie, takie jak przestawione litery oraz błędy ortograficzne, np. nazwa dzielnicy Bieżanów jest zapisana „przez rz”. W sytuacji, gdy takich przypadków jest kilka, można je szybko poprawić ręcznie, jeśli natomiast jest ich dużo, to warto ułatwić sobie to zadanie i zautomatyzować cały proces.
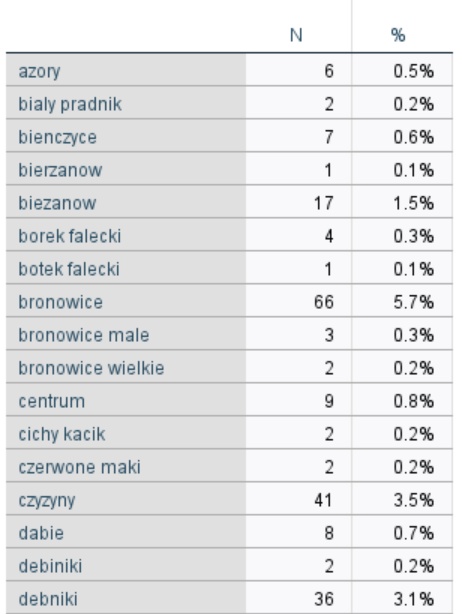
Rysunek 3. Fragment tabeli przedstawiający nazwy dzielnic Krakowa po ujednoliceniu
W kolejnym kroku chcemy porównać dwa ciągi znaków, aby określić na ile one są do siebie podobne. Do ich porównania wykorzystamy tzw. fuzzy matching. W PS IMAGO PRO mamy możliwość wyliczenia miar podobieństwa pomiędzy zmiennymi tekstowymi. Jak to obliczyć? Wszystko zależy od przyjętej miary odległości. Może to być liczba działań edycyjnych, które należy wykonać, aby dwa teksty stały się identyczne (wstawienia, usunięcia, zamiany znaków), możemy też porównywać tekst znak po znaku i obliczyć liczbę znaków, które nie są takie same. Opis dostępnych miar odległości został przedstawiony w wpisie Fuzzy matching w PS IMAGO PRO.
Jednym z algorytmów wykorzystywanym w fuzzy matchingu jest dystans Levenshteina. Dystans w tym przypadku odnosi się do określenia liczby znaków, jaką trzeba zmienić w jednym ciągu, aby uzyskać drugi. Im wartość wynikowa jest większa tym dwa ciągi znaków w większym stopniu różnią się między sobą.
W naszym przykładzie wykorzystamy dystans Levenshteina z poprawką na transpozycje znaków (Optimal String Alignment – OSA-Levenshtein). Od podstawowej wersji OSA Levenshteina różni się tym, że przestawienie kolejności dwóch znaków liczone jest za 1 działanie.
Zanim przejdziemy do wykonania procedury Porównaj tekst musimy wykonać jeszcze działania na danych, które pozwolą na poprawne wykonanie porównań. W danych mamy już zmienną z ujednoliconymi znakami, natomiast potrzebujemy jeszcze przykładów, do których program porówna zmienną źródłową. W tym celu powinniśmy przygotować tyle zmiennych, ile jest kategorii do porównania. W tym przykładzie będzie to 18 cech. Poszczególne zmienne to dzielnice Krakowa. Należy pamiętać, aby nazwy dzielnic również były ujednolicone pod względem znaków.
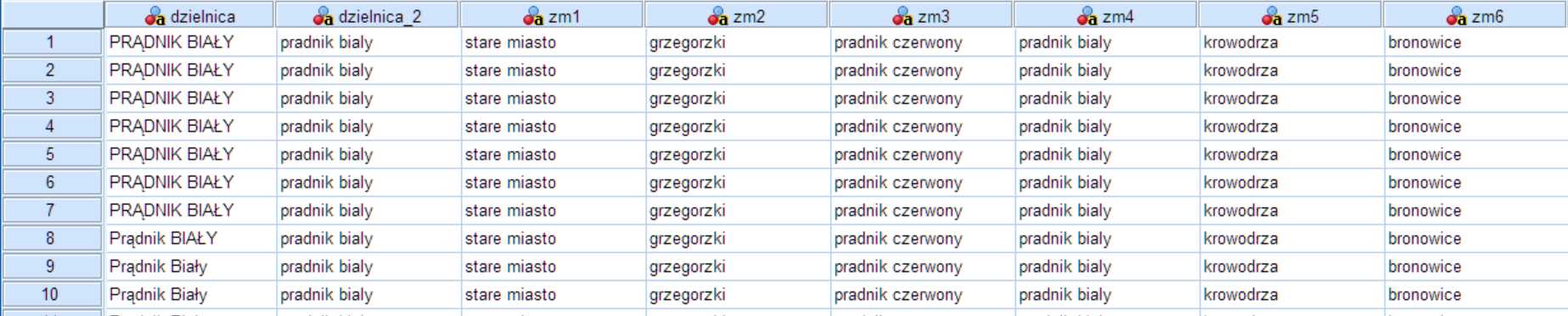
Rysunek 4. Dodane zmienne z nazwami dzielnic, które zostaną wykorzystane do porównania ze zmienną źródłową
Aby dodać zestaw zmiennych do porównania możemy zrobić to ręcznie z poziomu edytora danych za pomocą polecenia Oblicz wartości z menu Przekształcenia lub wykorzystać do tego poniższy syntax.

Następnie przechodzimy do menu Predictive Solutions -> Analiza -> Porównaj tekst. Do pola Zmienna źródłowa należy wskazać zmienną z badania, a do pola Zmienna porównywana wstawić zmienną zawierającą nazwę dla pierwszej sprawdzanej dzielnicy. W tym przykładzie użyję zmiennej dla dzielnicy Bieżanów. Następnie w polu Dostępne miary zaznaczymy dystans OSA Levenshteina, a z pola Dodaj zmienne zaznaczamy Ocena.
Po wykonaniu procedury do zbioru danych zostały dodane 2 nowe zmienne: osa_scr (ocena) oraz osa_sim (podobieństwo). Przeanalizujmy poniższy przykład.
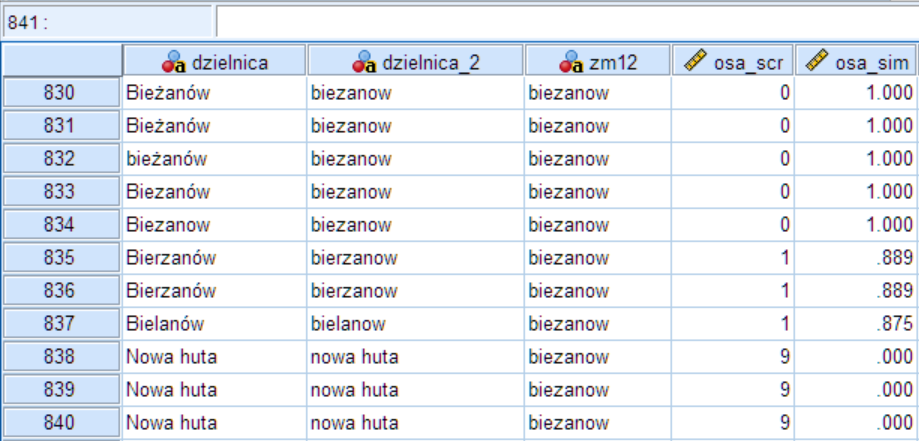
Rysunek 5. Po wykonaniu procedury Porównaj tekst, do zbioru dodane są dwie zmienne z oceną dopasowania
Na podstawie uzyskanych wyników należy określić próg podobieństwa, powyżej którego odpowiedzi zostaną uznane za odmiany tej samej dzielnicy, a wartości poniżej jako odpowiedzi respondentów dotyczące innej dzielnicy. Wartości podobieństwa powyżej tego progu kodujemy następnie jako 1 (czyli uznajemy, że mamy do czynienia z odmianą tej samej nazwy), a poniżej wartości progowej jako 0 (inne nazwy). Warto pamiętać, że przyjęcie zbyt wysokiego progu może spowodować nieprawidłowe odrzucanie teoretycznie prawidłowych nazw, natomiast przyjęcie zbyt niskiego spowoduje obecność dużej ilości szumu i nieprawidłowości wśród zakodowanych wartości. Warto przetestować różne wartości progowe i ocenić rezultaty zanim przejdziemy do ostatecznego kodowania zmiennych.
Działanie można następnie wykonać dla pozostałych dzielnic, pamiętając aby przy kolejnej iteracji zmienić nazwę zmiennej z informacją o podobieństwie oraz ocenie. Cały proces można też zautomatyzować wykorzystując do tego poniższy syntax. Na potrzeby naszego przykładu, w syntaxie zostanie pominięta zmienna dotycząca oceny.

Kiedy mamy już przygotowany zestaw zmiennych z informacją o wartości dopasowania dla dzielnic, możemy następnie warunkowo przekształcić te zmienne tak, aby otrzymać jedną zmienną numeryczną. Następnie dla każdej wartości w tej zmiennej dodamy odpowiednią nazwę dzielnicy jako etykietę. W naszym przykładzie wartością progową, powyżej której uznamy, że nazwa dzielnicy jest zgodna z wzorcem będzie 0,800. Tego rodzaju przekształcenie można wykonać z poziomu edytora danych za pomocą polecenia Oblicz wartości z menu Przekształcenia lub wykorzystać do tego poniższy syntax.

W rezultacie naszych działań otrzymamy zmienną z skategoryzowanymi odpowiedziami. Jak widać w tabeli poniżej nie występują już powtórzenia kategorii, zapis nazw dzielnic został ujednolicony za pomocą procedury Wyczyść tekst, a niewielkie literówki w nazwach udało się wykluczyć za pomocą procedury Porównaj tekst.
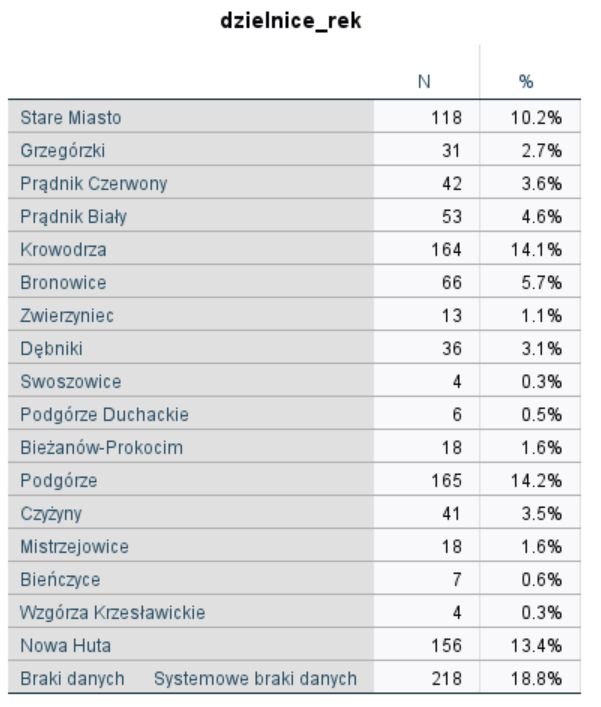
Rysunek 6. Tabela częstości przestawiająca nazwy dzielnic po skategoryzowaniu pytania otwartego
Analizy prezentowane w tym artykule zostały zrealizowane przy pomocy PS IMAGO PRO
Podsumowując, korzystając z procedury Wyczyść tekst oraz Porównaj tekst, możemy przyspieszyć oraz ułatwić pracę z danymi tekstowymi. W przypadku funkcjonalności Wyczyść tekst procedura wykona za nas pracę polegającą na usuwaniu zwielokrotnionych znaków, zamiany znaków diakrytycznych, czy też usunięcia niepotrzebnych znaków. Procedura Porównaj tekst może również być przydatna przy kategoryzacji danych tekstowych. W tym celu możemy szukać w wypowiedziach określonych słów, których wystąpienie może wskazywać, że dana wypowiedź dotyczy jednej z przyjętych przez badacza kategorii.
